|
Jaewoo (Jeffrey) Heo Hey! I'm Jaewoo (Jeffrey), an ML researcher at the Stanford MARVL (Medical AI and ComputeR Vision Lab) where I am advised by Professor Serena Yeung-Levy. I am also a part of Stanford Vision and Learning Lab, where I work with Professor Fei-Fei Li and Professor Ehsan Adeli in the Partner in AI-Assisted Care (PAC) group. I received my B.S. in Computer Science with Honors from Stanford University in 2024, and my M.S in Computer Science from Stanford University in 2025. Throughout my career in ML, I've been primarily involved with computer vision and medical AI research. My recent works in query-agnostic deformable cross attention, score distillation sampling with diffusion models, long-form video understanding, and VLM for reliable data generation aim to develop machines with enhanced spatiotemporal understanding of our world. In my free time, I enjoy playing the guitar, writing music, playing tennis, and watching soccer. I am a huge fan of The Beatles, Pink Floyd, and Billy Joel. I used to never be able to listen to music while coding, but I've recently developed a knack for putting on some bossa nova while working. |

|
Research"Understanding the problem is half the solution" My research interests lie in computer vision and deep learning for perception and spatiotemporal understanding to make meaningful inferences of the world. Specifically, I'm passionate about applied ML research particularly in the fields of robotics and autonomous vehicles. My work aims to bridge the gap between technical innovation and real-world application. |
|
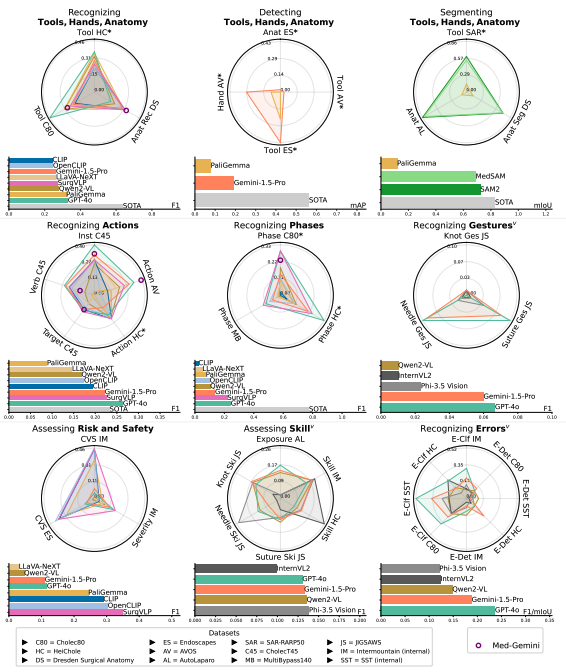
Systematic Evaluation of Large Vision-Language Models for Surgical Artificial Intelligence
Anita Rau, Mark Endo, Josiah Aklilu, Jaewoo Heo, Khaled Saab, Alberto Paderno, Jeffrey Jopling, F. Christopher Holsinger, Serena Yeung-Levy arXiv, 2025 project page / arXiv / code (coming soon) Evaluated 11 state-of-the-art VLMs across 17 surgical AI tasks using 13 datasets, demonstrating VLMs' superior generalizability compared to supervised models when deployed outside their training environments |
|
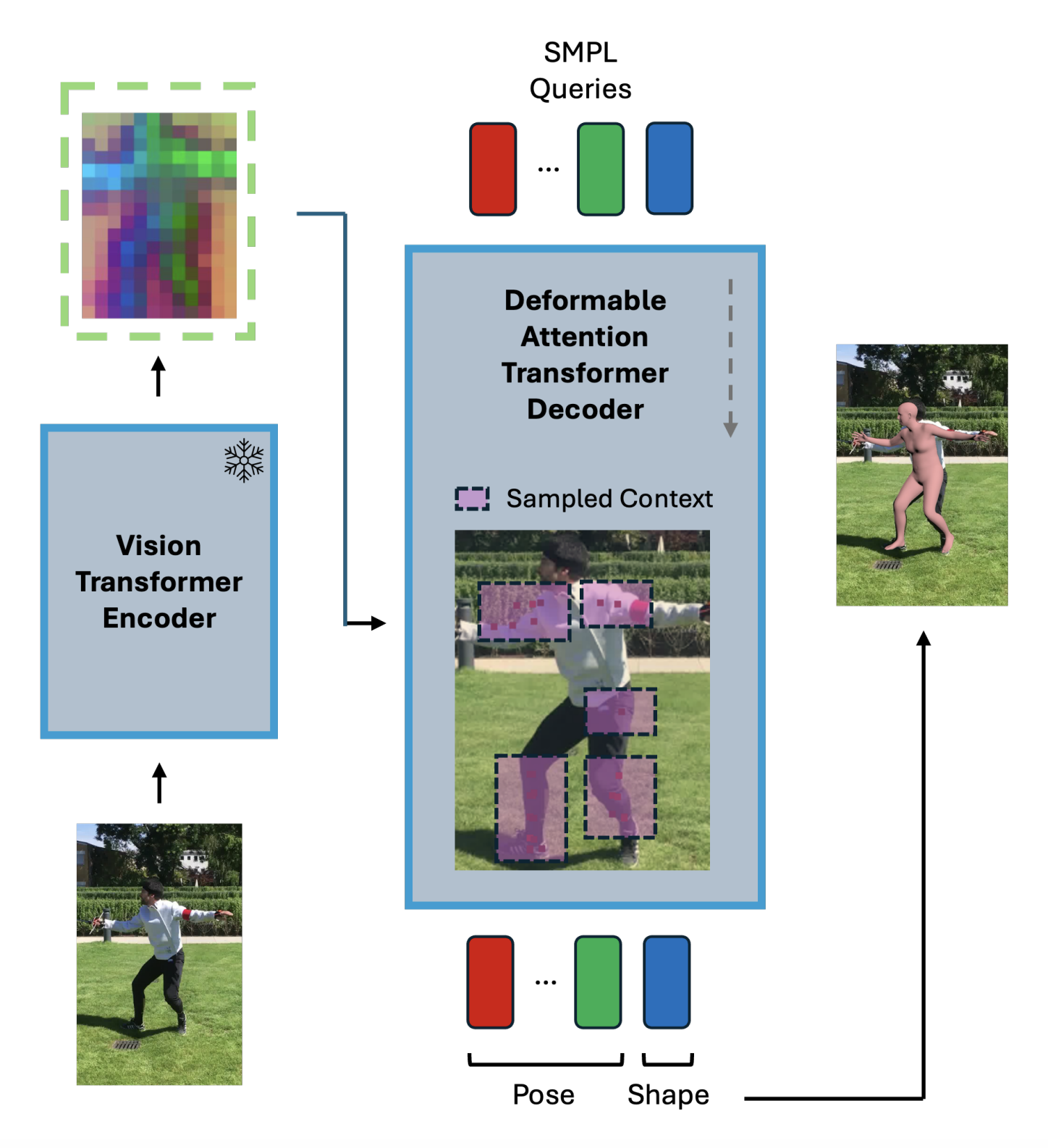
DeforHMR: Vision Transformer with Deformable Cross-Attention for 3D Human Mesh Recovery
Jaewoo Heo, George Hu, Zeyu Wang, Serena Yeung-Levy 3DV, 2025 (accepted) project page / 3DV'25 Camera-ready / code (coming soon) Proposes a novel query-agnostic deformable cross-attention mechanism that allows the model to attend to relevant spatial features more flexibly and in a data-dependent manner. Achieves SOTA performance on 3D human mesh recovery benchmarks 3DPW and RICH. |
|
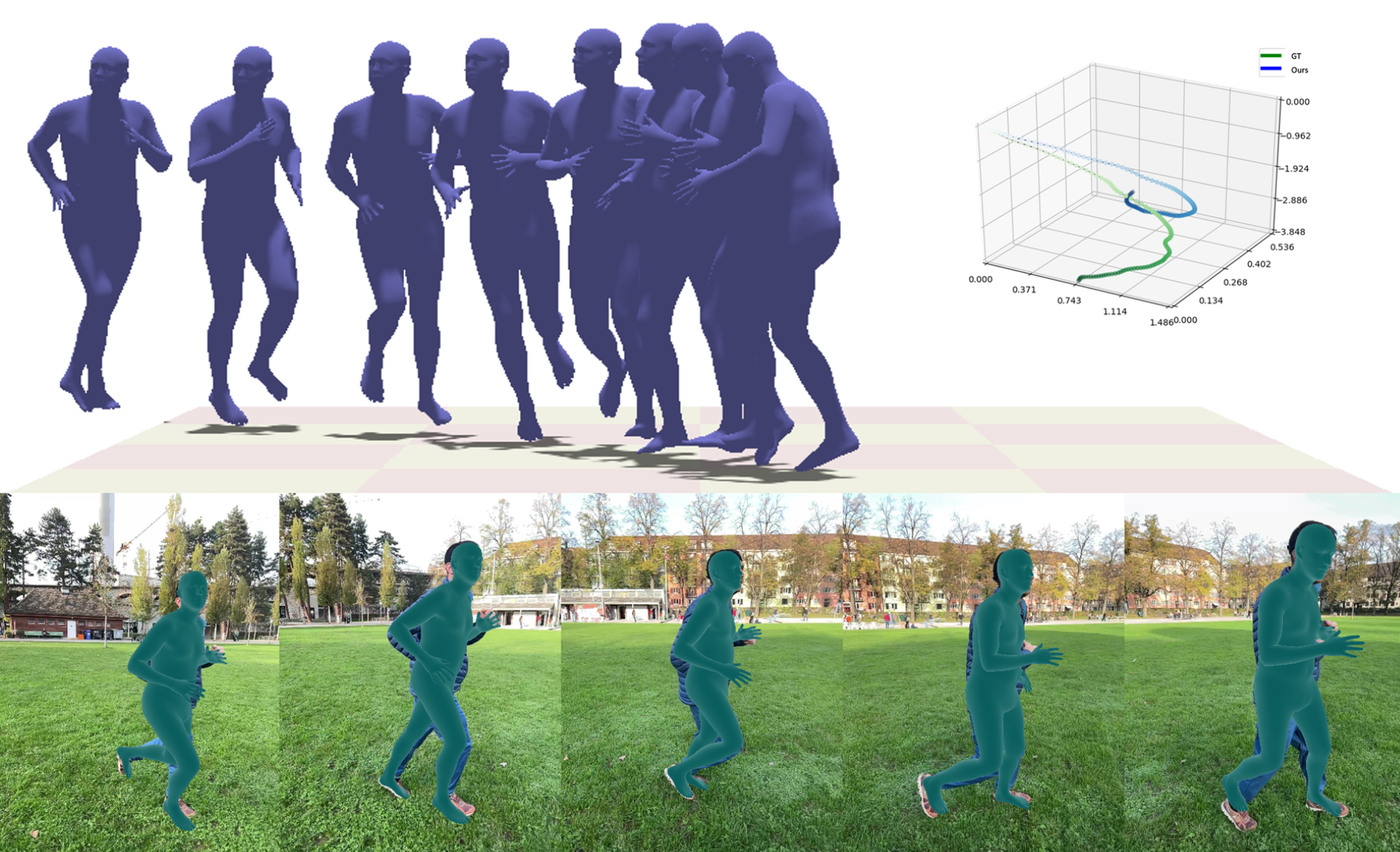
Motion Diffusion-Guided 3D Global HMR from a Dynamic Camera
Jaewoo Heo, Kuan-Chieh Wang, Karen Liu, Serena Yeung-Levy arXiv, 2024 project page / arXiv / code (coming soon) A 3D global HMR model that leverages the motion diffusion model (MDM) as a prior of coherent human motion. The model is robust to dynamic camera motion and long videos. |
|
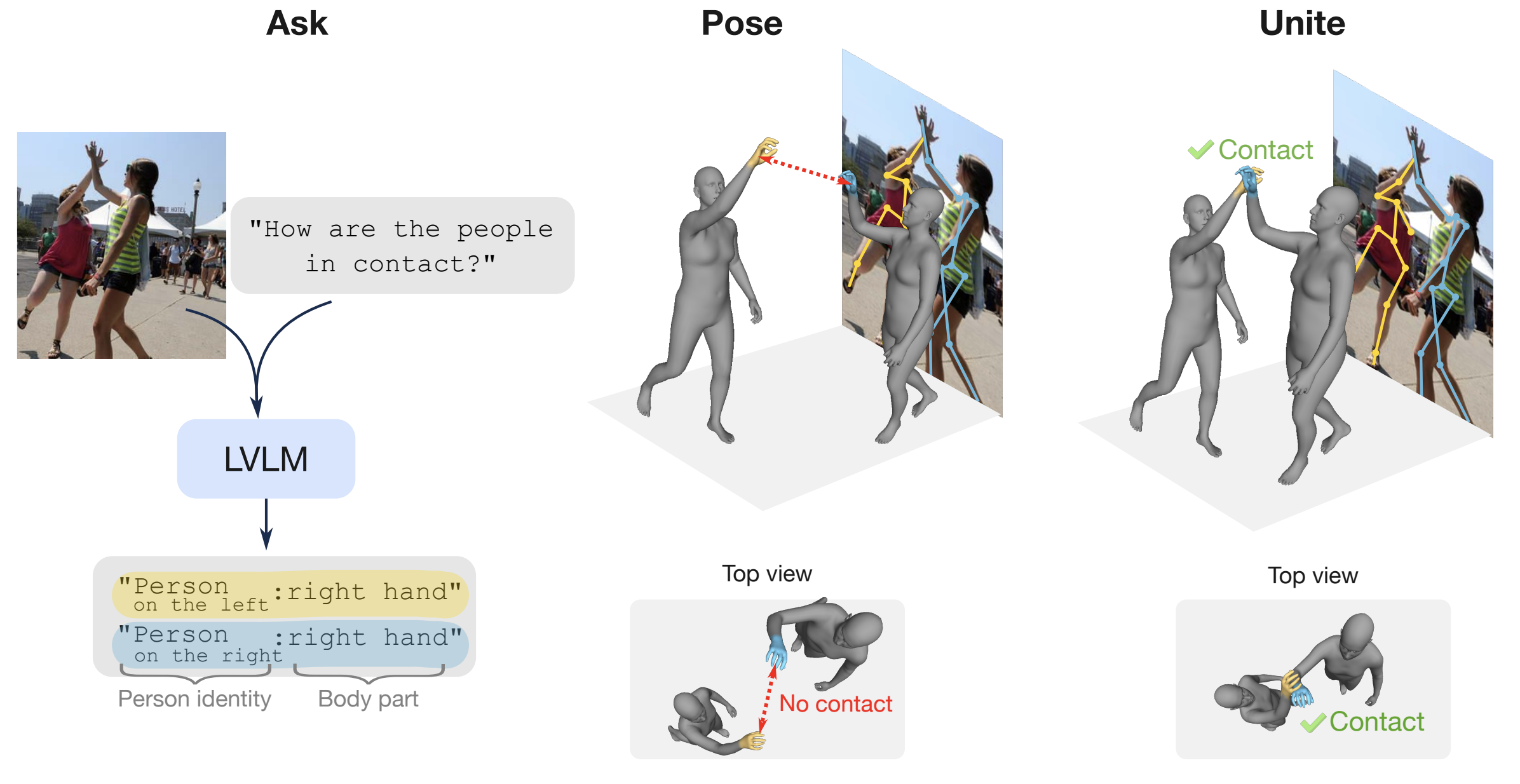
Ask, Pose, Unite: Scaling Data Acquisition for Close Interactions with Vision Language Models
Laura Bravo-Sánchez, Jaewoo Heo, Zhenzhen Weng, Kuan-Chieh Wang, Serena Yeung-Levy CVPR, 2025 (submitted) project page / arXiv / code (coming soon) Proposes a novel data generation method for close interactions that leverages noisy automatic annotations to scale data acquisition, producing pseudo-ground truth meshes from in-the-wild images. |
|
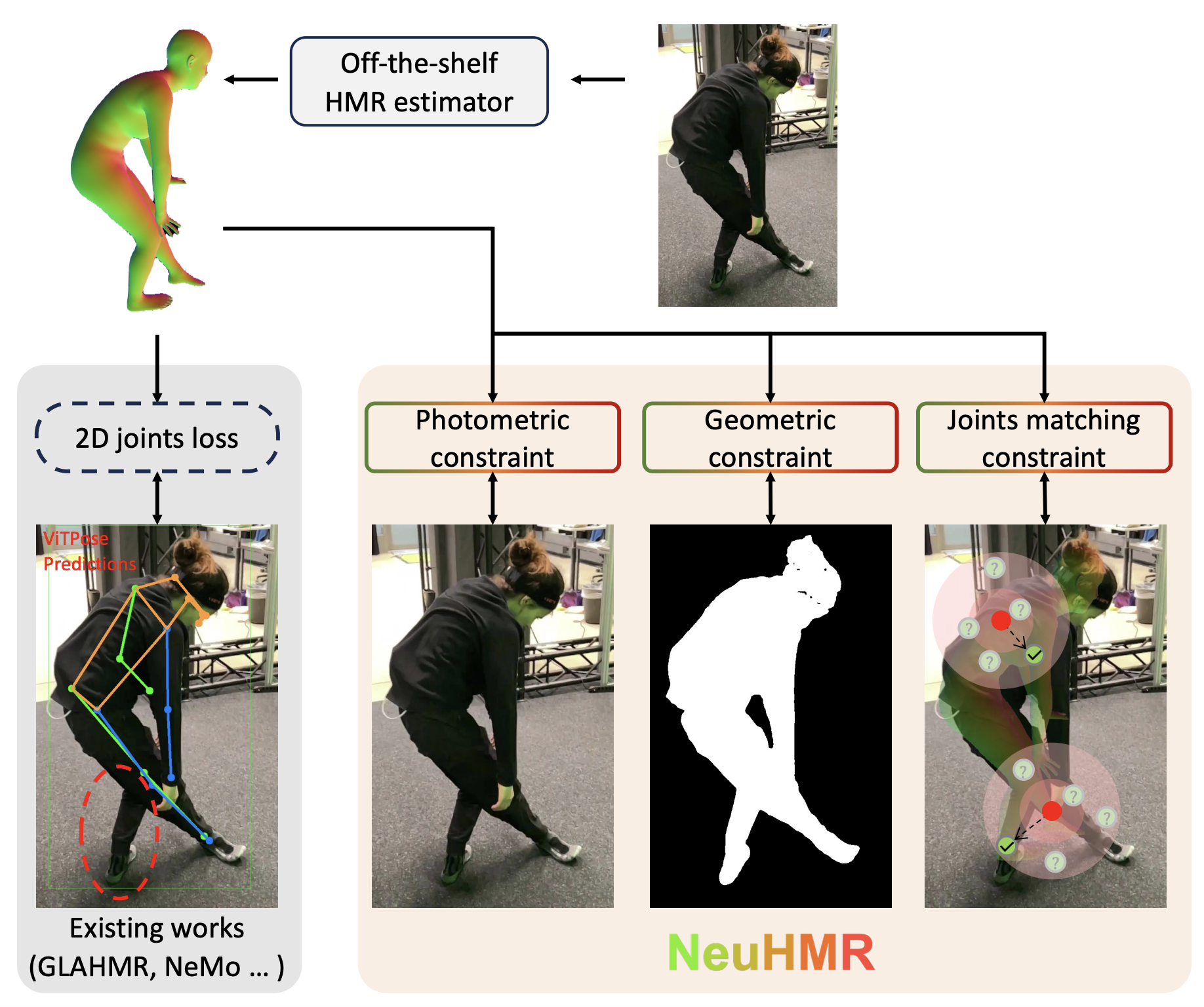
NeuHMR: Neural Rendering-Guided Human Motion Reconstruction
Tiange Xiang, Kuan-Chieh Wang, Jaewoo Heo, Ehsan Adeli, Serena Yeung-Levy, Scott Delp, Li Fei-Fei 3DV, 2025 (accepted) project page (coming soon) / arXiv (coming soon) / code (coming soon) Rethinks the dependency on the 2D key point fitting paradigm and presents NeuHMR, an optimization-based mesh recovery framework based on recent advances in neural rendering (NeRF). |
|
I referred to this website's source code to build my own. |